I Dépendances
Afin de permettre au projet de compiler sur un maximum d'OS , nous cherchons a reduire au maximum les dependances envers des librairies exterieures. Dans cette optique, la plupart des libraries non necessaires au fonctionnement du projet ne sont utilisee qu'optionnellement (le script configure se chargeant de les detecter). Ainsi, la libjpg , qui permet de lire/ecrire des fichiers jpg n'est utilisee n'est pas necessaire. Si l'utilisateur ne l'a pas installe, il ne sera juste pas en mesure d'utiliser des textures en jpg, mais pourra quand meme utiliser notre logiciel.
Norme ANSI C++ & Posix 2.2 :
Afin d'avoir un projet le plus portable possible nous avons décidé de nous conformer au norme ANSI C++, afin d'éviter tout problémes à la compilation; Ainsi que la norme Posix 2.2 pour éviter les problémes de dépendances vis à vis de telle ou telle librairie propriétaire.
OpenGL :
Notre projet incluant un prévisualisateur rapide, nous avons choisi OpenGL pour l'affichage. Cette librairie/API graphique a l'avantage d'être disponible sur la quasi-totalité des unix, ce qui ne remet pas en cause la portabilité de zRcube. OpenGL a l'avantage d'être suffisament flexible et facile à mettre en oeuvre pour réaliser rapidement le pré-visualisateur. En outre OpenGL permet un rendu suffisament rapide pour se permettre à l'utilisateur de se balader en temps réel dans la scéne, afin de vérifier que tout est bien chargé par exemple.
Cette librarie est optionnelle, l'utilisateur n'ayant pas openGL installe ne pourra tout simplement pas utiliser la preview.
GTK :
Tool-kit bien connu pour sa facilité de mise en oeuvre a été adopté par de nombreux projets pour leur interface graphique, ce qui fait que ce tool-kit est très répendu dans le monde UNIX. Afin de réaliser l'interface graphique du front-end, qui permettra de lancer plus facilement zRcube.
Le front-constitura fort probablement une application indépendante, gtk n'est donc absolument pas indispensable. Cette possibilité de pouvoir utiliser zRcube sans interface graphique est pour nous très importante, car elle permettra de lancer des calculs sur des gros serveurs, ceux-ci ayant rarement X-window installé (et encore moins gtk).
libjpg : Une librarie particulierement portable permettant de lire et ecrire des images jpeg, optionnelle.
libpng : Une librairie permettant de lire/ecrire des images au format png (Portable Network Graphics), optionnelle.
II Librairie 3D
Afin de réaliser rapidement un logiciel de l'importance de zRcube, qui utilise massivement les calculs et plusieurs concepts mathématiques. Il semblait normal de réaliser des outils de base afin de faciliter les implémentations future. C'est dans cette esprit qu'on étaient concus les classes "Matrix" et "Vector", ces deux classes d'objet devraient faciliter grandement l'implémentation des fonctions purement 3D de zRcube.
Les principales fonction mathématiques ont été implémentées sous forme d'opérateurs, ce qui facilitera grandement leur utilisation par les programmeurs.
Matrix :
permet de modéliser les opérations 3D usuelles, qui seront nécéssaires à la mise en place de zRcube :
Rotation autour des axes Ox, Oy, Oz, et d'un axe arbitraire.
Translation.
Mise à l'echelle.
En outre la plupart des opérations usuelles des matrices sont implémentées :
Multiplication (par une autre matrice, par un vecteur, où par un nombre).
Addition de matrice.
Ainsi que d'autres opération usuelles comme l'affectation, la comparaison etc ...
Vector : cette classe modéliser un vecteur composé de 3 nombres flottants.
Ici aussi la plupart des opérations usuelles ont étée implémentées :
Multiplication
Addition
produit scalaire, produit vectoriel.
Ainsi que d'autres opération usuelles comme l'affectation, la comparaison etc ...
III Librairie Image (libpic)
Notre projet utilisera massivement les images, que ce soit pour le texturage des objets d'une scéne, où de façon plus évidente pour sauver les images qui ont étées calculées. Ainsi la librairie de chargement d'image devait être en tête de la liste des choses à réaliser rapidement pour le projet.
Nous nous sommes attachés au chargement des formats d'image les plus utilisé dans POV, car si la syntaxe du format POV n'impose aucun format d'image, certains format ce sont imposés d'eux même dans les modeleur pour POV et POV lui même ne supporte qu'une dizaine de format parmi les plus courants, on a donc intéret à les supporter si on veut avoir suffisament de scénes de qualité à rendre avec zRcube.
Actuellement les formats d'images supportés le sont uniquement en lecture, mais la plupart des formats seront rapidemment disponbles en écriture afin de sauvegarder les images rendues par zRcube.
IV Templates
Parmi les outils les plus utiles dans une grosse application, il y a les Listes, cela fait parti des choses dont on a tout le temps besoin. C'est pourquoi il a ete decide de faire rapidement un Liste gemerique.
Afin d'avoir d'etre flexible au maximum, nous avons decider d'utiliser des templates, et de definir une classe virtuel, afin d'avoir une interface commune a tout les types de listes.
Templates : Introduit avec le C++, les templates permettent de realiser des conteneurs d'objet generiques tres facilement. Malheureusement les divers compilateurs ne les traitent pas toujours de la meme facon a la compilation. Ce qui fait que parfois un objet utilisant les templates compilera parfaitement avec tel compilos mais sera refuse par un autre.
Ainsi, afin d'eviter les probleme de compilation sur tel ou tel compilateur, nous avons mis tout le code dans les headers ou les classes sont definis. Meme si cela peut paraitre peu propre, il s'agit de la solution la plus elegante que nous ayons trouvee.
Les 2 types de listes :
Il existe 2 types de liste :
Statique et dynamique, la premiere utilise des bloques contenant un nombre d'element definisable par l'utilisateur. Cela permet d'economiser la memoire, et de gagner une peu en rapiditee lors de l'acces aux differents memebres de la liste. Mais on perd en rapidite au niveau de l'ajout et de la suppression.
La liste Dynamique par contre, est une pure liste chainee. Elle permet d'ajouter et de supprimer rapidement les elements, mais elle prend plus de temps a lire et consomme plus de memoire a cause des pointeurs supplementaires.
V Serveur CVS
Le projet regroupant 4 personnes, le travail en équipe devient un des points les plus sensibles du projet. Il faudra bien veiller au partage des informations, et cela le plus rapidement possible, afin d'éviter les conflits et les collisions intenpestive. Pour cela de nombreux logiciels de developpement ont été concus, parmi ceux là CVS rencontre un franc succés. Dans un premier temps, il était envisagé de mettre en place un serveur CVS dédié au projet. Toutefois la lourdeur de l'opération rendait la chose un peu trop couteuse en temps pour être vraiment rentable. Ainsi le projet est hebergé par sourceforge.net, un serveur CVS qui permet deja à de nombreux projets de fonctionner de maniére harmonieuse.
Autre avantage de sourceforge.net, il permet à tous ceux qui s'intéressent au projet de le suivre au jour le jour sans pour autant faire partie de l'équipe de developpement. En outre sourceforce.net propose des services intéressant pour les developpeurs, comme l'hebergement du site web.
Les possibilités de CVS facilite réelement le travail en équipe, ainsi chacun peut avoir accés à tout moment à la derniére version du logiciel sans avoir à le demander aux autres. En outre cela permet de gérer plusieurs version de fichier, on peut ainsi les récuperer en cas de fausses manoeuvres. De plus si 2 codeurs travaillent sur le même fichier, CVS peut le gérer en fusionnant les fichiers si il n'y a pas de conflit, où signaler les conflits sans appliquer directement les modifications.
VI Site Web
Afin de presenter notre projet au monde exterieur un site web a ete realise. Pour l'instant il n'a pas beaucoup de contenue vu que le projet est encore embryonnaire. toutefois la structure de base est la, et il devrait evoluer rapidement, et offriera a prioris plus de choses que les classiques cahier des charges et rapports de soutanance.
Afin de rendre le site un peu plus agreable, une partie de l'interface est en flash, qui est maintenant surpporte par la plupart des navigateurs recents, mais comme il existe encore une part non negligeable de navigateur plus ancien qui ne le supporte pas forcement, une version non flash sera aussi disponible.
VII Previewer OpenGL
Afin de mieux verifier la validitee des resultats revoyes par le parser et le module de radiositee, un previewer rapide utilisant OpenGL va etre mis sur place. Il devra permettre de verifier que les scenes lues par le renderer somt corretement interpretee, ou que les lightmaps calculee par le module de radiositee sont corrects.
Bien sur ce Previsualisateur ne serviera pas que pour le developpement, car il sera alors aise pour l'utilisateur d'avoir rapidement une idee de la scene qu'il va rendre.
Pour l'instant seuleument les objets simples de POV sont affiches par le Previewer (Cube / Sphere / Cylindre ...), mais des la deuxieme soutenance il devrait etre possible d'afficher des scenes complexe, avec un texturage basique quand cela sera possible.
VIII La polygonisation des objets
La mise en place du previewer a introduit le probleme de la polynisation des objets. En effet POV utilise des objets qu'il constuit avec des equations mathematiaues. Pour que ces objets soient utilisable avec OpenGL et dans le module de calcul d'illumination par radiosite, il faut en faire des objets polygonaux. Le principal probleme de la polygonisation est que l'on perd du detail.
Afin de pallier a cela, le niveau de detail sera ajustable. Chaque objet sera polygone en utilisant son systeme d'equation parametrique, le niveau de detail sera obtenu en faisant varier la precision du parametre "t", qui est la seule variable des equations. On pourra ainsi obtenir tres facilement et de facon transparente pour l'utilisateur le niveau de detail, sans avoir a faire du cas par cas.
II Algorithmes (Jean-Baptiste)
Nous de présenterons ici que des algorithmes généraux, leurs implémentation faisant l'objet de la soutenance suivante. En conséquence, nous ne detaillerons pas les structures de données utilisées ni les sous-fonctions nécessaires au fonctionnement des l'algorithmes mais dont l'explication n'est pas nécessaire a la compréhension de celui-ci.
Il existe deux principaux algorithmes de rendu, chacun avec ses avantages et ses inconvenients : le ray-tracing et la radiosité. Nous commencerons par les expliquer avant de présenter la manière dont nous les combinerons.
I Le raytracing (lancer de rayon)
1. Principe
L'algorithme utilise les lois de la réfraction et de la réflection d'un rayon lumineux en inversant la propagation physique d'un rayon : on part de l'oeil, passe à travers chacun des pixels du plan de l'image vers l'environnement. Pour calculer la couleur de chaque pixel de l'image, on lance un rayon à partir de l'oeil à travers chaque pixel jusqu'a ce qu'il rencontre un objet. On calcule alors la couleur du point d'intersection, en prenant en compte la couleur de la texture et l'influence des différentes lumières sur ce point.
Dans le cas de surfaces réflectives (par exemple un miroir) ou réfractive (par exemple un verre d'eau), il existe, en application des lois de la réflexion et de la réfraction, un rayon réfracte et un rayon réfléchi. Lorsque le rayon rencontre un tel objet, ces deux rayons sont donc générés, et sont à leur tour "lancés". On a donc une procédure récursive. A chaque réflexion et réfraction, l'énergie du rayon baisse, la récursion est stoppée lorsque cette énergie peut être négligée. La couleur du pixel est alors une combinaison de la couleur du point d'intersection (dépendant de la texture et des lumières), de celle renvoyée par le rayon réfracté et de celle renvoyée par le rayon réfléchi.
Il est intéressant de noter que ce principe inclut implicitement la gestion des ombres portées : si un point d'intersection ne « voit » pas de lumière, alors il sera noir (car l'influence des lumières sur lui est sera nulle) , ce qui correspond a dessiner une ombre.
La figure 1 illustre ce principe (tous les rayons réfractés et réfléchis ne sont pas dessinés afin de simplifier le dessin).
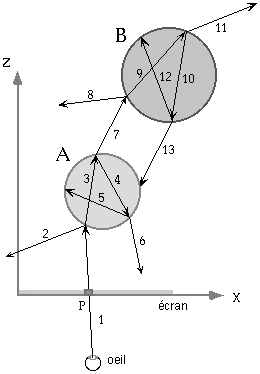
Figure 1
Le rayon incident 1 peut etre partiellement réflechi (2) et partiellement réfracté (3) lors de la première intersection avec la surface A. Une partie des rayons réfléchis et réfractés est montrée (5,6). Ces rayons, peuvent ensuite générer à leur tour des rayons refractés, etc ... L'algorithme apparait donc naturellement recursif.
On peut représenter l'execution de cet algorithme sous la forme d'un arbre binaire, chaque noeud correspondant à une intersection, la couleur d'un noeur resultant de la somme des couleurs renvoyées par son sous-arbre droit et son sous-arbre gauche. La figure 2 présente l'arbre correspondant à la figure 1.
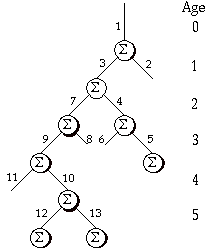
figure 2
La récursion doit notamment se terminer si:
- Le rayon rencontre une lumière
- L'intensité du rayon est tres faible, en raison de l'absorbtion
- Le rayon est piégé dans un objet transparent
- Le rayon sort de la scène.
2. Calculs des angles de réflection et de refraction
Le principe énoncé précédemment montre qu'il est primordial de pouvoir calculer exactement la direction du rayon réfracté et celle du rayon réfléchi, c'est ce que nous donne les lois de Descartes.
a. Première loi de Descartes :
Le rayon incident, le rayon réfracté, le rayon reflechi et la normale au point d'incidence sont coplanaires.
b. Deuxième loi de Descartes : angle de réflexion
Soit P une surface , l'angle que fait la normale à P avec le rayon incident est égal à celui que fait le rayon réfléchit avec cette même normale.
c. Troisième loi de Descartes : angle de réfraction
Soit une surface P, M1 et M2 deux milieux d'indices de réfraction respectifs n1 et n2.
on a : Sin(Thetai)/sin(Thetar) = nr/ni
N1 et n2 sont connus (on notera particulièrement que l'indice de réfraction du vide vaut 1) , on trouve donc aisément : Theta r = asin( sin(Thetai) * ni / nr)
La figure 2 illustre ces lois.
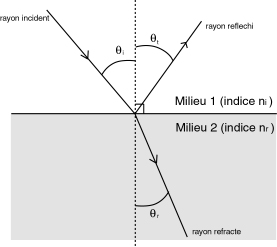
Figure 2
3. Calcul de l'influence des lumières
Nous ne traiteront pas cette section dans les détails car nous utiliseront un autre algorithme pour gérer l'illumination.
Lorsque le rayon lancé rencontre un objet , on trace les droite reliant ce point a chacune des lumières de la scène (on appelle parfois ces droites des « shadow ray s» ). Considérons une droite D reliant un point et une lumière. Si cette droite a au moins un point d'intersection avec un objet de la scène, alors la lumière n'aura aucune influence sur la couleur du point d'intersection (dans ce cas , l'objet est a l'ombre). Si l'objet rencontre est transparent , la lumière n'est qu'atténuée.
Il est nécessaire de réitérer cette opération pour chacune des lumières de la scène.
4. Algorithme récursif du ray-tracing
Afin de garder un algorithme lisible , nous ne détaillerons pas toutes les fonctions , on suppose codées les fonctions :
On fixe de plus la condition d'arret de la recursion au facteur d'attenuation (qui equivaut à la hauteur de l'arbre)
- Intersection = point x polygone x rayon : booléen Cette fonction renvoie vrai en cas d'intersection du rayon ray avec un des objets de la scène. Dans ce cas , elle place le point d'intersection dans point , et la normale a la surface d'intersection dans vecteur. Dans le cas de plusieurs intersection , elle renvoie les données correspondant a l'intersection la plus proche du point de départ du rayon. Nous reviendront sur les calculs d'intersection dans la section concernant l'utilisation de l'octree .
- CalculeReflect : point x vecteur : rayon : calcule le rayon réfléchit
- CalculeRefract : point x vecteur : rayon : calcule le rayon réfracté
- On suppose que l'ensemble des fonctions peuvent accéder a l'ensemble des objets de la scène (en ajoutant un pointeur sur la scène a toutes les fonction , par exemple)
Algorithme procédure trace : couleur
Paramètres locaux
Rayon ray
Entier energie
Variables
Point3d point
Polygone poly
Rayon refl_ray , refr_ray
Couleur col
Début
Si (energie <= ENERGIE_ MIN) alors
Rentourne(NOIR)
Sinon
Si ( intersection (point, poly, ray) ) alors
Col <- poly^.texture[point]
Refl_ray <-calculeReflect(point ,poly)
Col := col + trace( Refl_ray , energie - 1) * poly^.coeff_reflectivite
Refr_ray <- calculeRefract(point ,poly)
Col <- col + trace( Refr_ray , energie - 1) * poly^.coeff_refraction
/* calculer l'influence de toutes les lumière sur col * /
Sinon
Retourne( NOIR)
Fin Si
Fin si
Fin algorithme
La récursivité peut difficilement être évitée, le principe du ray-tracing incluant une récursivité. De plus, l'algorithme équivalent en version itérative est beaucoup plus compliqué.
Pour rendre une image complete, il suffit d'appliquer cette procédure à l'ensemble de rayons issus de l'?x0153;il et passant par chacun des points de l'écran.
5. Parallelisation
L'algorithme de ray-tracing peut être parallélisé car le calcul de chacun des rayons est indépendant du calcul des autres. On peut donc utiliser un algorithme du type (N désignant le nombre de processus )
Variables :
Entier i,j
Début
J<- 0
Pour tous les rayons
Processus[ j ].Trace (rayon, ENERGIE_ MAX)
J<- (j+1) mod N
Fin Pour
Fin algorithme
Dans notre implémentation, c'est la libnet (voir 2 ) qui se charge de répartir le calcul, la parallélisation de l'algorithme est alors beaucoup simplifiée.
II La radiosité
1. Principe
a. Idée
Imaginons une salle avec quatre murs rouges et un sol blanc. En toute logique , le sol devrait être un peu rouge, car selon le modèle physique de la couleur, les murs rouges émettent de la lumière rouge. Or l'algorithme de ray tracing ne prend pas en compte cette interaction entre les surfaces, le but de la radiosité est de modéliser ce comportement afin d'obtenir un modèle d'illumination le plus proche de la réalité possible.
b. Une première approche
Equation de radiosité:
Puisque chaque surface émet de la lumière , on doit la considérer comme une source de lumière, mais elle reçoit aussi la lumière emise par toutes les autres surfaces, on doit donc la considérer aussi comme un capteur de lumière. On est donc amenés à associer à chacune d'elles deux valeurs : la quantité de lumière reçue (son « illumination » ) et la quantité de lumière en surplus qu'elle va émettre vers les autres (son « énergie radiative »).
Cependant, si l'on revient à un exemple concret, il apparaît évident qu'une surface, par exemple une table, ne reçoit pas une quantité uniforme de lumière. Dans le cas idéal, il faudrait diviser notre surface en surfaces de taille infinitésimales, ce qui reviendrait a représenter chaque surface sous la forme d'une intégrale et par conséquent a représenter l'ensemble des surfaces sous la forme d'une integrale.
On appelle form factor la fonction donnant la quantite d'energie donnée par une surface i à une autre.
On peut regrouper ces concepts de « balance d'énergie » dans la relation de radiosité :
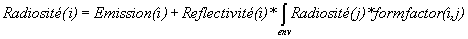 Avec :
Avec :
Radiosite(i) = Bi = Total de l'énergie quittant la surface. (homogène avec des W/m2 )
Emission(i) = Ei = Le niveau d'énergie émis par la surface (homogène avec des W/m2 )
Réflectivité(i) = pi = La fraction de l'énergie qui est réfléchie (sans dimension)
Integrale(env) = intégrale sur l'ensemble des surfaces.
Formfactor(i,j) = Fij
Cependant, il est très difficile de manipuler des données infinies en informatique, la solution généralement adoptée consiste à diviser chaque surface en surface les plus petites possibles, la qualité de l'image finale (c'est a dire le réalisme du modèle ) dépendant de la taille de ces surfaces. On appelle « patche » chacun de ces petits éléments de surface. On peut alors écrire l'équation de radiosité sous la forme (en considérant N patches):
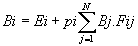 Solution de l'équation de radiosité :
Solution de l'équation de radiosité :
Puisqu'il y a N patches, chacun interagissant sur les autres, on est amené à résoudre un systeme linéaire à N équations et N inconnues, que l'on peut aisément resoudre, avec par exemple la méthode de Gauss.
La figure 3 illustre un tel système avec 4 patches.
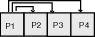
rad(p1) = E(P1) + rad(p2)*F12 + rad(p3)*F13 + rad(p4)*F14
rad(p2) = E(P2) + rad(p1)*F21 + rad(p3)*F23 + rad(p4)*F24
rad(p3) = E(P3) + rad(p2)*F32 + rad(p1)*F31 + rad(p4)*F 34
rad(p4) = E(P4) + rad(p1)*F41 + rad(p2)*F42 + rad(p 3)*F43 |
figure 4
c. Calcul du form factor
Cette fonction doit dépendre de l'angle que font les deux surfaces entre-elles, de la visibilités d'un surface par rapport à une autre (si elles sont séparées par un mur , le form factor sera nul, si elle sont séparées par une fenêtre, cela devra influer sur le form factor) et de la distance entre elles. D'après Cohen & Greenberg [?x2026;], on peut ecrire le form factor sous la forme :
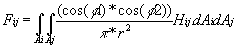 où
où
Ai = aire du patche de départ
Aj = aire du patche d'arrivée
r = distance entre A1 et A2
Hij = fonction de visibilité :
Hij vaut 1 si dAi peut « voir » l'element dAj, 0 sinon. Dans le cas de surfaces transparentes, il peut avoir une valeur intermédiaire. Son calcul sera abordé plus en détail dans la section concernant l'octree.
Puisque nous avons simplifié notre équation pour travailler avec des quantités finies, on peut finalement écrire le form factor :
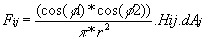 Mais cette solution n'est pas encore utilisable dans le cadre de zRcube. En effet, si l'on prend l'exemple d'une scène à 5000 polygones (ce qui est très petit ), chaque polygone étant divisé en 100 patches, on est amené à résoudre un système à 500 000 inconnues ! On a par consequent besoin d'une matrice de 500 000 x 500 000 , ce qui nous fait 250 000 000 000 éléments, ce qui est bien sûr impossible compte tenu de la taille de la ram d'un PC.
Mais cette solution n'est pas encore utilisable dans le cadre de zRcube. En effet, si l'on prend l'exemple d'une scène à 5000 polygones (ce qui est très petit ), chaque polygone étant divisé en 100 patches, on est amené à résoudre un système à 500 000 inconnues ! On a par consequent besoin d'une matrice de 500 000 x 500 000 , ce qui nous fait 250 000 000 000 éléments, ce qui est bien sûr impossible compte tenu de la taille de la ram d'un PC.
d. La radiosité à affinage progressif (progressive refinement)
La solution consiste à ne pas chercher à résoudre le système d'un coup -ce qui a de plus le désavantage d'empêcher l'utilisateur de voir l'image se former.
Pour cela , on sélectionne le patch qui a le plus d'énergie et on distribue son energie à tous les autres patches. On répète l'opération jusqu'à ce que le patch le plus brillant (celui qui a le plus d'energie) n'ai qu'une quantité d'énergie négligeable. On n'a ainsi pas besoin de stocker la matrice, on gagne ainsi beaucoup de mémoire .
2. Parallelisation
Nous avons vu que , contrairement au cas du ray-tracing, chaque calcul de radiosité est dependant de tous les autres, ce qui rend la parallelisation de cet algorithme beacoup plus difficile. Cependant, de nombreuses methodes ont été developpées recemment. Certaines emploient une autre approche de la radiosite , sans form factor [14], d'autres cherchent à partitionner les données [3]. Nous avons choisis d'utiliser la méthode décrite par L. Sindlar [4], qui consiste à repartir le calcul du form factor : en effet, le form factor met en jeu deux cosinus (ce qui n'est pas grand chose sur nos pc actuels) mais surtout une fonction de visibilité. Celle-ci utilise de nombreux tests et calculs, en conséquence, la faire calculer par le client /autre cpu peut s'avérer etre un gain de temps important. Nous avons aussi sélectionnés cette approche car elle nous a paru moins compliquée à mettre en oeuvre que les autres que nous avons envisage.
La encore, la répartition du calcul est faite par la libnet, en consequence les algorithmes parallele et standard sont similaires : la seule différence étant au niveau du calcul du form factor , la version standard la calculant directement, alors que la version parallèle demande au serveur de le calculer pour lui.
3. Algorithme
Là encore, nous de détaillerons pas l'implémentation de chaque fonction, mais juste l'algorithme principal.
On suppose que le type Patche est une structure contenant les données comme le coefficient de reflexion, le coefficient d'émission, la quantité de lumiere incidente (d_rad) et la quantité de lumière émise (d_deltaRad).
La fonction calculeFormFactor() applique le calcul expliqué précédemment, de même, la fonction calculEquatioRadiosite effectue le calcul DeltaRad = pi *Fij comme décrit precedemment.
algorithme procédure radiosité
Paramètres globaux
Liste de patches L
Variables
Patches pSrc, pDest, pNext
Reel FF , double
Début
Tant que ( (pSrc = ChercheLePatcheLePlusBrillant(L) ) <> NUL ) faire
PDest <- premier(L)
Tant que pDest<>NUL faire
FF <- calculeFormFactor(pSrc,pDest)
Si FF<>0 alors
Deltarad <-calculeEquationRadiosite(pSrc ,Pdest)
pDest^.d_deltaRad <- Pdest^.d_deltaRad + deltaRad
pDest^.d_rad <- <- Pdest^.d_rad + deltaRad
Fin si
Fin tant que
PSrc^.d_deltaRad <- 0.0f
Fin tant que
Fin algoritme procédure radiosité
4. Aspect pratique
Pour chaque patche, cet algorithme permet d'obtenir une valeur(un triplet de valeur puisque l'on travaille en RGB) correspondant à la couleur et a l'intensité de la lumière reçue par ce patche. En regroupant plusieurs de ces valeurs, on peut former une image , généralement appelée « Lightmap » (on peut par exemple générer une lightmap par face). Pour obtenir la scène éclairée , il suffit alors de multiplier la texture de chaque face (ou sa couleur) par la lightmap correspondante.

III Notre algorithme
1 . Idée
Si l'on fait le bilan de ce que sont capable de gérer ce deux algorithmes séparément, on obtient :
|
Effet géré |
Effet non géré |
| Raytracing |
- Réflexion des objets
- Réfraction
- Illumination à partir de sources ponctuelles (spots) ou globales (Lumières ambiantes).
|
- Réflexion des lumières
- Prise en compte de l'influence lumineuses des surfaces entre elles.
|
| Radiosité |
- Réflexion des lumières
- Prise en compte de l'influence lumineuses des surfaces entre elles.
|
- Réflexion des objets
- Réfraction
|
On peut trouver des images montrant les differences entre ces deux algorithmes dans [9].
Les deux algorithmes apparaissent donc parfaitement complémentaires, et dans l'optique du rendu d'une image de la meilleure qualité possible (la plus réaliste possible), il paraît nécessaire de les combiner. Nous proposons un algorithme en deux passes le permettant.
2. Notre algorithme
L'algorithme de radiosité permet une gestion plus réaliste de l'illumination que celle apportée par le raytracing, mais ce dernier permet un meilleur rendu final. Notre idée est donc de commencer par calculer l'illumination de la scène, via l'algorithme de radiosité , ce qui constitue une première passe. ¨Puis , on rend la scène en utilisant l'algorithme de ray tracing, sans prendre en compte les lumières, mais en appliquant les lightmaps.
On doit donc modifier légèrement l'algorithme de raytracing pour que, au lieu de renvoyer la couleur du point d'intersection, il renvoie cette couleur multipliée par celle de la lightmap correspondante, on doit aussi supprimer le calcul de l'influence des lumières sur cette couleur, puisque celle-ci est déjà prise en compte par la lightmap.
On obtient l'algorithme (évidemment simplifié):
Algorithme fonction rendre : pointeur sur image
Paramètres locaux
Scène S
Liste de Lightmap L
Pointeur sur image pic
Début
L <- CalculerLaRadiosité (S)
Pic <- RayTracingModifié(L ,S)
Retourne(pic)
Fin algorithme fonction rendre
Une rapide analyse de la parallelisation des algorithmes que l'on utilisera (cf partie II) montre que nous avons besoin que le serveur transmette au client une collection de valeur (un couple de patches dans le cas de la radiosité, un rayon dans le cas du raytracing) et que le client doit renvoyer un ensemble de résultats (une couleur dans le cas du raytracing, un flottant dans le cas de la radiosité).
On aimerait en conséquence pouvoir demander au server "présente nous le résultat du calcul sur ces valaurs". Pour une utilisation la plus intuitive possible, cela devrait même être la seule fonction publique du serveur.
Du côté du client, la meilleure idée apparait être de lui donner la fonction de calcul, et qu'il lance lui même cette fonction sur les données qu'il reçoit.
De plus, nous n'avons pas encore implémenté ni le ray tracing ni la radiosité, en conséquence il sérait très ambitieux de dresser une liste exhaustive des valeurs que nous aurons à transmettre. Notre librairie doit donc être capable de transmettre sur le réseau des paquets de données de taille quelconques, celle-ci étant de type quelconque. On pourrait ainsi, si on le désirait, transmettre un int et deux float au client, celui-ci nous renverrait par exemple 3 float.
Enfin, il parait absurde de lancer plusieurs clients sur une même machine (afin de pouvoir utiliser plusieurs cpu sur une machine multiprocesseurs) et de communiquer via le réseau d'où la nécessite de pouvoir utiliser des "clients virtuels" s'executant sur la même machine que le serveur, mais pouvant accéder directement aux données en ram du serveur, et ainsi gagner beaucoup de temps.
1.Organisation
La description de notre besoin met en évidence que la nécessité d'au moins deux objets : un objet serveur et un objet client.
Cependant, serveur et client auront tous deux à utiliser de nombreuses fonctions très similaires : ouvrir une sockette, envoyer/recevoir des données dessus... D'o&urgave; la nécessite de créer un objet socket, se plaçant comme une interface aux sockettes BSD.
2. Algorithmes et principes
a. Le principe des patterns
Afin de pouvoir transmettre un nombre quelconque de données d'un type quelconque, nous devons spécifié le modèle des données transmises lors de l'initialisation du client et du serveur. Pour cela, nous avons mis en place un pattern sur le modèle de printf: une chaîne de caractère du type "%<type1> %<type2>" où <type> peut être n'importe lequel des types de base (int, float, char, double, string...). Ce pattern est compatible avec les chaines de formatage utilisée par printf et scanf. Pour chaque objet, il existe un pattern de réception et un d'émission, car rien n'oblige le client à renvoyer des données du même type que celles envoyées par le serveur.
b. La négociation
Avant de transmettre les données, le serveur doit s'assurer du type des données qu'il va échanger avec les clients. A la connection d'un client, le serveur débute donc une "négociation" : il demande au client ses differents patterns et vérifie qu'ils concordent avec les siens. Lors de cette négociation, nous comptons inclure les résultats d'une évaluation des performance du client, afin de permettre au serveur de répartir ses calculs en fonction de la vitesse de chaque client, mais cette partie n'a pas encore été codée.
c. Le serveur
Nous voulons que le serveur tourne dès qu'il est initialisé, afin de pouvoir ajouter des clients sans interrompre l'ensemble du programme. De même il nous a paru interessant de permettre à des clients de se connecter alors que le calcul est déjà commencé et de les inclure dans la boucle de calcul. Pour cela, nous devons donc réaliser deux tâches en parallèle, ce qui nécessite l'utilisation de threads (l'utilisation de la fonction fork étant à proscrire étant donne qu'elle duplique la ram et donc ne permet pas le partage des données). Une introduction aux threads posix peut être trouvée dans [16]
Lors de l'initialisation du serveur, celui-ci commence donc par créer une sockette d'écoute, puis lance un thread qui se chargera d'attendre la connection d'un client. Pendant ce temps, le reste du programme continue à s'executer normalement. Si un client se connecte, la négociation est alors lancée, et en cas de réussite, le client est ajoute a une liste chainée circulaire maintenue par le serveur.
Lorsque l'on demande au serveur de calculer pour un ensemble de données, il commence par incrémenter sa liste de clients, puis envoie les données à ce client. Puisque la liste est circulaire, il envoie donc successivement les données à chaque client.
d. Le client
Le client est très simple : il se connecte au server, envoie ses patterns quand ce dernier les lui demande, puis a chaque fois qu'il reçoit des données, il leur applique sa fonction de calcul et renvoie le résultat au serveur.
Lorsque nous avons voulu tester la libnet a l'école (elle avait été initialement developpée sous Linux), nous avons été surpris que, si aucune erreur n'etait generée, il ne se passait rien ! Lorsqu'un client se connectait, le serveur ne le prenait pas en compte.
Nous avons commencé par regarder si cela n'etait pas un problème de réseau : La fonction d'attente du serveur aurait pu être bloquée sur la primitive accept suite a une mauvaise initialisation des sockets de notre part.
Cependant, après quelques tests, il s'est avéré que le thread ne se lançait tout simplement pas du tout. Nous avons donc commence à investiguer du cote des threads. Nous avons rapidement remarque que la lib pthread (le p signifie posix) de netBSD n'etait en fait qu'une interface a la librairie gnu pth (<pth.h>, le p signifie portable). Or, la documentation [16] de cette librairie précise que afin d'obtenir une portabilité maximum, cette bibliothèque permet de créer et de manipuler que des threads coopératifs, et non pas préemptifs (les threads posix correspondent à des threads préemptifs), contrairement a la librairie pthread disponible sous Linux (Linux Threads).
Notons les principales différences lorsque l'on code avec des threads coopératifs au lieu de thread préemptifs :
- un thread doit laisser explicitement la main au sheduler, celui-ci la donnant alors a un autre thread. Dans le cas de la Gnu Pthread, on peut notamment utiliser la fonction pth_yield(NULL). Notons que cette fonction n'existe pas dans les spécifications posix.
- toute fonction bloquante (par exemple la primitive accept() est par défaut bloquante) bloque l'ensemble du processus, et non pas juste le thread ou elle est lancée, comme dans le cas de thread préemptifs. La fonction sleep() arrête elle aussi l'ensemble des threads alors que dans un modèle base sur un multitâche préemptif, elle n'arrête que le thread ou elle est lancée.
Ainsi, un thread utilisant une boucle codée avec des threads posix :
while(1){
/*instructions*/
}
doit être transformée en
while(1){
/*instructions*/
pth_yield(NULL);
}
Cette différence a nécessite de nombreux changement dans notre code pour être prise en compte.
Il est important de noter que des threads coopératifs sont inutiles a notre projet. En effet, rappelons les raisons qui nous ont pousse à utiliser des threads :
- la possibilité d'une abstraction supplémentaire et d'une souplesse de programmation en permettant de à la fois traiter l'arrivée d'un client, mais aussi de continuer les calculs. Avec les threads coopératifs, cela n'est possible qu'au prix de nombreux passage explicite de la main aux autres threads, ce qui revient quasiment à appeler à chaque boucle de calcul une fonction qui regarderait si un nouveau client etait connecte. Un effet similaire a l'utilisation de threads coopératifs aurait pu être d'utiliser le signal ALARM. Les threads coopératifs ne sont donc probablement pas la solution la plus simple pour un résultat équivalent dans ce cas.
- la possibilité d'utiliser des machines multiprocesseurs, chaque thread de calcul (clients virtuels) s'exécutant sur un processeur. Les threads coopératifs sont tous intègres a un même processus. En conséquence, ils ne peuvent être repartis sur plusieurs cpus, et donc sont inutiles.
En vue de ces nombreux désavantages, nous avons été tentes de recoder les parties utilisant les threads et en les recodant avec un algorithme itératif qui nous aurait assure un maximum de portabilité. Cependant, il aurait été dommage de priver les utilisateurs d'OS disposant d'une librairie gérant les threads préemptifs (linux, solaris ...) de la possibilité de repartir le calcul sur plusieurs cpus (les machines bi-processeurs étant de plus en plus courantes). En conséquence nous avons décide de continuer a utiliser les threads et de rajouter des pth_yield() inclus lorsque le projet est compile avec la librairie Gnu Pthread (via des directives de precompilation, la détection de la librairie étant faite par le script configure).
Ma premiere tache dans ce projet est le parseur POV. C'est la partie du programme final qui prend en entré un fichier
texte comprenant un descriptif de scene de type POV-Ray, et qui construit tous les objets representant cette scene en memoire.
Avant de pouvoir commencer le parseur, il faut donc ecrire les classes de tous les objets qui pourraient etre trouvés dans dans
la norme POV.
1. Objets de base
Heureusement, la documentation de POV-Ray est bien faite, et j'ai donc trouvé tout ce qu'il me fallait assez rapidement:
Sphere, Box, Cylinder, Cone, Plane, Disc
Il y a d'autres objets plus complexes ( height fields, fractals ...) mais nous avons decidé de ne pas le supporter pour l'instant.
Avant de commencer, j'ai tout d'abord téléchargé le code source de POV-Ray (www.povray.org), pour voir comment les auteurs avaient tout
construit, et pour trouver toutes les propriétés des objets.
Apres avoir survolé tout le code quelques fois et rendus quelques images avec POV-Ray pour me remémoriser ses possibilités, j'avais en tête
la structure que j'allais utiliser.
Le projet est réalisé en C++, donc nous pouvons utiliser l'heritance de classes, ce qui facilite beaucoup les choses. Notre
code sera beaucoup plus facile a maintenir et relire que celui de POV.
2. Description des propriétés de base
J'ai donc créé une classe Object, qui servira de classe de base pour tous les objets, qui ont tous les memes propriétés de base:
int type;
int flags;
Object *sibling;
Object *bound;
Object *clip;
Texture *texture;
Interior *interior;
BBox *bbox;
type:
Le type est un champ de bits qui correspond a des informations sur cet objet qui seront
utilisées plus tard pour le ray-tracing.
Dans POV, il existe treize differents types, que je n'enumérerai pas ici, mais voici quelques exemples:
Le bit 2 nous indique si cet objet possede une texture, le bit 3 nous indique s'il a des fils (elements suivants dans une liste chainée),
le bit 6 nous indique si cet objet est une source lumineuse...
Chaque puissance de 2 correspondant au bit est defini par une constante (ex: #define TEXTURED_OBJECT 2).
flags:
Flags est similaire au type, c'est un autre champ de bits.
Le premier bit indique que l'objet ne provoque pas d'ombre, le bit 2 indique que l'objet est fermé...
Comme pour le type, chaque bit a une constante (ex: #define NO_SHADOW_FLAG 1).
*sibling:
Sibling est un pointeur vers un autre objet, qui sera utilisé plus loin pour construire les listes d'objets a rendre.
*bound:
Un autre pointeur d'objet qui pointe vers un objet moins complexe qui entoure l'objet.
Ceci sera utilisé plus loin pour les tests d'intersections avec les rayons.
*clip:
Propriété encore non definie. Elle ne sera peut-être pas utilisée.
*texture:
Un pointeur vers une structure de texture, structure qui n'a pas encore été implémenté, j'y reviendrai plus tard.
*interior:
Un pointeur vers une structure Interior, structure qui servira a determiner les rayons presents dans les objets pour
le tracé de rayons. Ici aussi, j'y reviendrai avec beaucoup plus de details lors de la partie Ray-Tracing.
*bbox:
Un pointeur vers une bounding box. Une bounding box est un ensemble de deux vecteurs qui definissent une boite
qui entoure tout l'objet. Cet element est utilisé pour accelérer l'algorithme qui cherche des intersections
dans tous les objets. Avant de calculer le point precis d'intersection du rayon avec l'objet, on regarde
s'il y a une intersection avec la bounding box, ce qui est plus rapide a calculer. Si ce n'est pas le cas, il ne
sert a rien d'essayer avec l'objet lui meme.
J'ai ensuite definis des fonctions qui permettront de mettre des bits a 1 ou 0, et de tester tous les champs possibles
dans Type et Flags, a partir des constantes definies.
3. Derivation des classes d'objets
Une fois la classe Object definie, j'ai pu la deriver pour créer les vrais objets. Chaque objet aura donc les propriétés
de base de la classe Object, et sera complété par ses propriétés particulières.
Voici une definition generale de chaque objet:
class <NomObjet> : public Object
{
// Propriétés locales a cet objet
public:
// Fonctions Constructors de cet objet
// Fonctions Interface
// Fonctions Generales
};
Les propriétés locales de l'objet Sphere sont un centre et un rayon.
Les fonctions constructeurs sont les initialisations possible de l'objet quand il est créé.
Les fonctions interface sont les fonctions qui permettent de recupérer les propriétés (qui ne sont pas publiques),
et de les remplir (ex: Sphere::setRadius(float r) { radius = r; } ).
Les fonctions generales sont toutes les fonctions qui viendront plus tard pour la suite du projet (ex: intersection de rayons..)
4. Objets speciaux
Il y a aussi les objets speciaux, qui ne sont pas forcement dérivés de la classe Object.
Pour l'instant, j'ai commencé la base des objets Ray, Camera, et LightSource. LightSource est le seul
objet a être dérivé de la classe Object, c'est un point lumineux qui servira de lumière pour les calculs de radiosité et
le tracé de rayons.
La Camera contient des vecteurs qui definissent son emplacement dans la scene, son orientation et des paramètres
d'effets speciaux (ex: focal blur, field of view) qui seront utilisés pour le ray-tracing.
Et Ray, c'est un ensemble de deux vecteurs (origine et direction), munit d'une liste chainée de structure Interior, pour savoir dans
quels objets un rayon est present a n'importe quel moment du tracé de rayon, notamment pour calculer l'attenuation
d'intensité.
Une fois les objets de base definis, je pouvais commencer le parseur (Henri commencait le preview OpenGL, avant de me rejoindre
plus tard sur le parseur).
Je me suis donc remis dans les sources de POV pour voir comment les auteurs avaient fait. Le code est immense, et rien
n'est general. Le fait que ce soit du C et non du C++ ne facilite pas la lecture.
Le parseur POV est fait de deux sous parties: un Tokenizer et le Parseur proprement dit.
Le Tokenizer ce charge d'extraire des expressions regulières du fichier, en les passant sous forme de Token
au Parseur, qui gère les règles de grammaire pour construire la scène en memoire.
Je me suis donc mis sur le net a la recherche de documentation détaillée sur les grammaires et le parsing.
Heureusement, j'avais fait un exposé sur le sujet l'année dernière, donc il me restait nombreuses docs,
et je n'avais pas encore tout oublié.
1. Definition d'un langage formel
a. Definitions
Un vocabulaire est un ensemble fini de symboles:
V = { a, b, c, ..., z }
Une chaîne sur un vocabulaire V est une concaténation de symboles:
x = ab
La concaténation de deux chaînes a pour résultat une chaîne obtenue en juxtaposant ces deux chaînes:
avec x = ab et y = cd, on obtient xy = abcd.
V* est l'ensemble de toutes les chaînes sur le vocabulaire V. Par définition un
langage est un sous-ensemble de V*. C'est un ensemble de chaînes construites
avec ce vocabulaire.
b. Propriétés
Il est important de se rappeler que les langages sont des ensembles construits sur des vocabulaires
donnés, il faut donc toujours spécifier le vocabulaire associé à un langage.
Réunion: Si L est la réunion des langages L1 et L2, il est composé des
chaînes appartenant à L1 ou à L2 ou aux deux.
Intersection: Si L est l'intersection des langages L1 et L2, il est composé
des chaînes appartenant à L1 et à L2.
Concaténation: Le produit par concaténation de deux langages L1 et L2
contient toutes les chaînes formées par la concaténation d'une chaîne de L1 avec
une chaîne de L2.
Extension: L'extension d'un langage, noté L* est la réunion de tous les
langages obtenus en élevant le langage à toutes les puissances entières (non
négatives). Exemple : si L = { a, b, c, ..., z }, L* est l'ensemble de toutes les chaînes
de longueur quelconque formées des lettres de L.
2. Notions de grammaire formelle
a. Introduction
On rappel qu'un langage naturel est un sous-ensemble de l'extension d'un certain vocabulaire.
Une grammaire doit donc au moins servir à définir quelles sont les chaînes qui appartiennent à un langage.
Sur le plan formel, une grammaire est un système constitué d'un nombre fini de composants et destiné à la description d'un langage.
Système de production:
Un système de production est un couple (V, P) où V est un vocabulaire fini de symboles et P est un
ensemble fini de productions.
Les productions ont la forme x -> w où x et w sont des chaînes sur V (mais
x ne peut être vide), c'est-à-dire x appartient a V+ et w appartient a V*.
Pour définir un système de productions, il sufit de définir ses deux composantes V et P. Ainsi:
V = {a, b, c } et P = [ba -> ab, ca -> ac, cb -> bc]
constituent un système de productions.
a -> b est une dérivation directe, et a => b est une dérivation indirecte, qui peut être décomposée en
une suite de dérivations directes.
b. Définition d'une grammaire formelle
Une grammaire formelle est un quadruplet:
G = {Vn, Vi, P, S}
où V t est un vocabulaire terminal fini. C'est sur ce vocabulaire que sont formées les chaînes (phrases)
du langage que la grammaire définie. Ces chaînes appartiennent donc à Vi*.
Vn est un vocabulaire non terminal fini. C'est un vocabulaire auxiliaire utilisé dans les règles
de grammaire. Le plus souvent Vn contient les éléments du métalangage utilisé pour dénommer les constituants.
Vn et Vi n'ont aucun élément en commun; le vocabulaire V de la grammaire est la réunion de Vn et Vi.
Le couple (V, P) est un système de productions. P est un ensemble de productions, appelées dorénavant
règles de la grammaire de la forme :
x A y -> z , tel que A appartient a Vn, et x,y,z appartiennent a Vi*.
Les deux membres d'une règle sont appelés "partie gauche" et "partie droite": la partie gauche
contient toujours au moins un élément de Vn ; si l'on considère chaque règle x -> y comme un couple (x, y),
on peut alors dire que P est un sous-ensemble du produit cartésien V+ X V* .
S est un élément particulier de Vn appelé le symbole initial ou axiome de la
grammaire. Une grammaire n'a toujours qu'un seul symbole initial.
Le langage défini par une grammaire G s'écrit L(G). Une phrase de L(G) est
toute chaîne x de Vi*, telle que S => x. Le langage défini par une grammaire G est:
L(G) = { x / x appartient a Vi* et S => x }
3. Parseur POV
Quand il s'agit d'utiliser une grammaire pour réaliser un parseur, un nouveau mot-clef important
apparait: les Tokens.
Un token est l'unité atomique d'un langage. Il consiste d'une description de syntaxe et d'un type.
Une instance de token est appellé lexeme: une chaine de charactères qui conforme a la description syntaxique du token.
Le parseur doit donc lire les charactères du fichier, extraire les tokens, et s'assurer que les lexemes sont valides, avant
d'etablir de relations avec la grammaire.
Par exemple le token UNDECLARED_IDENTIFIER est renvoyé si on trouve un mot qui n'appartient pas
a l'ensemble de definition des identifieurs POV (ex: sphere, light_source, camera, ...).
Le vocabulaire est constitue de:
-symboles terminaux ("a", "b",... "Z", "0", ... "9", ".", ",", "}", ...)
-symboles auxiliaires ("|", "[", "]", "...")
-une suite de symboles terminaux est un identifier
-Un identifier entre crochets [] est optionel
- | signifie un ou (exclusif)
-Un identifier suivi de ... signifi qu'il peut y avoir une
concatenation d'instantiations de cet identifier.
a. Exemple raccourci de la grammaire POV
DIGIT:
0|1|2|3|4|5|6|7|8|9
EXP:
e|E
SIGN:
+|-
FLOAT:
[DIGIT...] [.] DIGIT... [EXP [SIGN] DIGIT...]
SPHERE:
sphere { FLOAT|VEC2D|VEC3D, FLOAT [OBJECT_MODIFIERS...] }
OBJECT_MODIFIERS n'est pas defini ici, normalement il le serait,
ce serait une liste de operations que l'on peut faire sur tous les objets (ex: texture, colour, normal, transform....).
b. Implementation
Il y a deux implementations possibles pour le parseur:
1) la grammaire est codé dans le parseur ("hard coded grammar").
Principe Algorithmique:
On utilise une fonction GetNextToken qui renvoye le prochain token trouvé dans le fichier.
Cette fonction renvoye 0 si la fin du fichier a été rencontrée.
Tant qu'on est pas arriver a la fin du fichier (tant que GetNextToken renvoye une valeur non-nulle),
on traite le token recuppéré. Le traitement ce fait cas par cas, sur tous les tokens possible.
Pour chaque type de token, on sait quel devrait être le prochain token, par rapport a la grammaire, donc
on renvoyer un message d'erreur si c'est un token non attendu.
Avantages: facile a réaliser.
Inconveniants: le code sera très grand, peu lisible, avec pleins de switch et de case partout, et on
pourra difficilement modifier les règles de la grammaire.
2) la grammaire est lu dans un fichier texte externe que l'on peut facilement modifier ("external grammar"):
Principe Algorithmique:
On utilise la meme fonction GetNextToken, mais il nous faut récuperer des tokens dans le fichier POV, et dans
le fichier grammaire, et ces tokens ne correspondent pas aux mêmes règles syntaxiques.
Tant qu'on est pas arriver a la fin du fichier (tant que GetNextToken renvoye une valeur non-nulle),
on traite le token recuppéré. Le traitement va donc aller chercher dans le fichier grammaire (ou dans la memoire
si on charge toute la definition de la grammaire en memoire dès le debut pour gagner du temps après) quel type
de token doit arriver après pour que la grammaire soit satisfaite. Si GetNextToken ne renvoit pas ce type
de token, on renvoye un message d'erreur.
Le fichier grammaire serait de la même forme que l'exemple plus haut.
La fonction qui renverrai le token attendu par rapport a la grammaire serait GetNextGToken,
par exemple GetNextGToken(SPHERE_TOKEN) renverrai d'abord LEFT_BRACE_TOKEN ("{"), puis FLOAT|VEC2D|VEC3D,
puis COMMA_TOKEN (",") ...
Le code du parseur serait donc beaucoup plus compacte que la version précedente, et on pourrait ajouter des règles de grammaire plus facilement.
Mais ca ne fait que reporter le probleme aux constructeurs d'objets: tout les cas particuliers fait dans le code du parseur 1)
devront être reportés dans chaque constructeur d'objet, qui doit savoir toutes les correspondances entre l'ordre des paramêtres.
Un petit exemple:
On sait que l'on est en train de construire une sphere (on a deja recupéré les tokens SPHERE_TOKEN et LEFT_BRACE_TOKEN).
Si le prochain token est un FLOAT_TOKEN (grammaire validée), et que l'on passe cette valeur au constructeur de sphere, il doit determiner
si il doit remplir sa variable Center ou Radius... Donc les switch sont dans le code des constructeurs, ce qui rend quand même le code un peu plus modulable.
Avantages: code compact et plus generalisé
Inconveniants: il ne faudrait pas qu'il y ait trop de cas particuliers, et il faut deux tokenizers.
Il faut aussi charger toutes les règles en memoire avant de commencer le parsing, donc on
rajoute le temps de chargement et le temps de recherche en memoire a la complexité generale.
4. Lex
Avant de me lancer dans l'implementation, j'ai suivi le conseil tres averti de Jean -Baptiste qui me disait de regarder s'il n'y avait
des outils unix (lex et yacc) qui pourraient me simplifier la tache.
J'ai donc trouvé des sites qui expliquaient le fonctionnement de ces programmes qui sont utilisés notamment pour faire des compilateurs, et
plus generalement tout ce qui traite du parsing (http://www.combo.org/lex_yacc_page/).
Ce sont deux programmes qui prennent du texte en entré et donnent du code source en sortie.
Ils sont concus pour être utilisés ensembles: lex créé une fonction qui va chercher les tokens dans l'input, et yacc utilise cette fonction pour
faire correspondre les tokens récupérés à des règles de grammaire.
Donc l'entré de lex est une definition syntaxique des tokens possibles, et l'entré de yacc est une definition grammaticale du langage que l'on cherche a parser.
En resumé, si j'utilise lex et yacc pour le parseur:
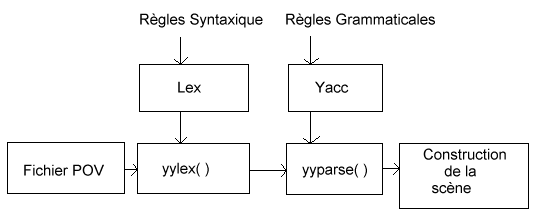
Je me suis donc plongé dans la documentation de Flex (une version optimisé de lex, qui fait pareil).
Le principe est assez simple, on lui donne un fichier qui contient des definitions et des règles sur les expressions regulières que l'on
veut qu'il trouve dans l'input.
a. Vocabulaire d'operateurs
Un vocabulaire special est utilisé pour les definitions et les règles :
" \ [ ] ^ - ? . * + | ( ) $ / { } % < >
Tous ces charactères rencontrés dans une definition correspondent a des operations
sur la chaine.
Quelques explications sur une partie du vocabulaire:
-Les crochets ( "[", "]" ) indiquent une classe de charactères (ex: [0-9] indique un chiffre entre 0 et 9, [a-zA-Z] indique
une lettre de l'alphabet minuscule ou majscule...)
-les curly brackets ( "{", "}" ) indiquent une derivation (ex: {ALPHA} sera remplacé par [a-zA-Z] )
-une barre ( "|" ) est utiliseé pour un OU exclusif.
b. Definitions
Le fichier contient d'abord une partie de definitions qui permettent de simplifier le reste:
DIGIT [0-9]
ALPHA [a-zA-Z]
ALPHANUM {ALPHA}|{DIGIT}
La partie gauche devient un symbole qui pourra être dérivé en sa partie droite si rencontré dans les règles.
Ce sont en fait une sorte de macros qu'un pre-processeur vient remplacer avant le vrai traitement.
c. Règles
Ensuite il y a la partie des correspondances expression-action, qui utilise le même vocabulaire special:
{DIGIT} return (DIGIT_TOKEN);
"{" return (LEFT_CURLY_TOKEN);
sphere return (SPHERE_TOKEN);
\n num_lines++;
La partie gauche est l'expression régulière et la partie droite est le code C qui y correspond.
Toutes les constantes *_TOKEN sont definies dans un fichier .h qu'on peut inclure au debut du fichier lex.
Quand une expression est trouvé dans l'input, le lexeme de ce token est mis dans une variable globale yytext.
d. Routines Utilisateur
Il y a une troisième partie dans le fichier lex, ou l'on peut mettre du code C.
En general on met la fonction main qui appelle la fonction yylex jusqu'a ce que celle ci renvoye 0, mais
dans le cas ou on utilise lex en externe, il suffit de definir la fonction yywrap.
Cette fonction sera appellé internement a lex quand la fin du fichier arrive a l'input. Si la fonction renvoye 1, cela
veut dire que le traitement est finie, si elle renvoye 0, cela veut dire qu'on s'est occupé de changer de fichier ou de changer
l'input et le traitement continue.
Pour l'instant ma fonction yywrap est:
int yywrap()
{
return 1;
}
Mais il se pourrait que je la change plus tard pour pouvoir traiter les #include dans les fichiers POV.
En effet, #include ouvre un autre fichier pour aller chercher des objets ou constantes POV deja definies, donc le traitement
arriverait plusieurs fois a la fin d'un fichier avant d'être terminé.
e. Classe Token
J'ai donc construit le fichier de definitions lex, et l'ai compilé avec flex, ce qui m'a donné un fichier C de 2000 lignes,
gain de temps et de travail immense (surtout pour du code facile et rebarbatif a faire), en rappelant que le but du projet est un
moteur de rendu et non un parseur.
J'ai ensuite créé une classe token qui inclut en externe la fonction yylex.
Cette classe contient des variables qui nous donne des informations sur le token actuel: position dans le fichier, type de token, chaine correspondante...
ainsi qu'une fonction GetNextToken qui utilise yylex pour remplir ces variables.
5. Yacc et conclusion
Pour l'instant je ne me suis pas encore servi de yacc, me concentrant d'abord sur la partie tokenizer.
J'ai cependant créé une classe Parser qui utilise la classe Token.
Cette classe a une fonction Parse qui prend en paramètre un token et qui fait un traitement dessus, comme decrit plus haut.
J'utilise une "hard coded grammar", je note cepedant les règles grammaticales dans un fichier texte pour reference.
Heureusement la documentation POV contient toute la grammaire du langage.
Cette classe est temporaire. Je l'utilise pour l'instant pour me donner une idée de comment marche un parseur, je vais surment utiliser
yacc pour gagner du temps et pour pouvoir commencer la partie ray-tracing.
Conclusion
Le diagramme 2 présente une synthese des differentes etapes menant du fichier decrivant la scene (le fichier pov) à l'image finale.
Enfin, pour conclure définitivement cette première soutenance, notre bilan à la fois personnel et de groupe nous paraît correct. En effet, nous respectons à cette date les directives imposées par l'échéancier de notre cahier des charges.
Ainsi, nous envisageons avec sérénité la suite de ce projet, en vous rappelant les objectifs fixés pour la prochaine soutenance :
- Implementation et optimisation d'un raytracer
- Implementation et optimisation d'un radiositeur